

Dans mon tutoriel précédent, j’ai montré comment installer Kubernetes sur Ubuntu 22.04 . Par contre, dans le monde IT, un an c’est une éternité. Avec la sortie de Ubuntu 24.04 LTS (Noble Numbat), les règles du jeu ont un peu changé, et les anciennes instructions ne donnent plus la stabilité qu’on attend. Et dans le cas d’une nouvelle installation, c’est toujours mieux de partir sur une version plus récente pour être tranquille.
Aujourd’hui, je vais montrer comment déployer un cluster sur la distro la plus récente. Même si le principe général reste familier, le « diable » est comme toujours dans les détails : des nouveaux standards pour le placement des clés GPG et les méthodes pour désactiver le SWAP via systemd, jusqu’aux configs spécifiques des ports du firewall.
En plus de la base, j’ai ajouté un bloc critique pour les vrais projets : la réservation des ressources système (Node Allocatable). On va apprendre à faire en sorte que le cluster se protège lui-même, pour que même les pods utilisateurs les plus « lourds » ne puissent pas faire planter l’OS ou les composants clés de Kubernetes.
Préparation de l’infrastructure
Pour cette démonstration, j’ai installé Ubuntu 24.04 sur 3 VMs tournant sous Proxmox. Chaque machine dispose de 4 cœurs CPU et 8 Go de RAM.
Note importante : Il est impératif d’utiliser des machines virtuelles (VM) et non des conteneurs LXC. Kubernetes a besoin d’un accès direct aux modules du kernel, ce qui rend l’installation complexe et instable dans un environnement LXC non privilégié.
Voici l’adressage IP utilisé pour ce guide :
Master (k8smast): 192.168.0.231
Worker 1 (k8swork1): 192.168.0.232
Worker 2 (k8swork2): 192.168.0.233
Sur tous les nodes, les commandes sont exécutées avec un utilisateur ayant les droits sudo. Pour plus de commodité, avant de commencer, il faut temporairement désactiver le firewall sur tous les nodes :
sudo ufw disable
On va le reconfigurer à la fin, une fois qu’on s’assure que tout fonctionne correctement.
Étape 1 : Configuration des hostnames et du DNS (sur tous les nodes)
On configure les noms d’hôtes (il faut exécuter la commande correspondante sur chaque machine) :
Sur le Master :
sudo hostnamectl set-hostname k8smast
Sur le Worker 1
sudo hostnamectl set-hostname k8swork1
Sur le Worker 2
sudo hostnamectl set-hostname k8swork2
On ajoute les entrées dans /etc/hosts sur les trois nodes pour qu’ils puissent se résoudre entre eux :
sudo tee -a /etc/hosts > /dev/null <<EOF # Kubernetes Cluster 192.168.0.231 k8sm k8smast.lan 192.168.0.232 k8sw1 k8swork1.lan 192.168.0.233 k8sw2 k8swork2.lan EOF
Si vous avez accès à un serveur DNS, c’est mieux de le faire là, mais vous pouvez aussi garder la config dans le fichier hosts pour plus de fiabilité.
Étape 2 : Désactivation du SWAP (sur tous les nodes)
Kubernetes exige que le SWAP soit complètement désactivé. Sur Ubuntu 24.04, on va le faire au niveau du kernel et de systemd.
1. Désactiver le SWAP actuel
sudo swapoff -a
2. Supprimer l’entrée dans fstab
sudo sed -i '/ swap / s/^\(.*\)$/#\1/g' /etc/fstab
3. Désactiver le swap via systemd (spécifique aux nouvelles versions Ubuntu)
sudo systemctl mask swap.target
Étape 3 : Configuration du kernel et des modules (sur tous les nodes)
Containerd et K8s ont besoin des modules overlay et br_netfilter, ainsi que du forwarding IPv4 activé.
Chargement des modules au boot
sudo tee /etc/modules-load.d/k8s.conf <<EOF overlay br_netfilter EOF
Appliquer immédiatement
sudo modprobe overlay sudo modprobe br_netfilter
Configuration sysctl pour Kubernetes
sudo tee /etc/sysctl.d/k8s.conf <<EOF net.bridge.bridge-nf-call-iptables = 1 net.bridge.bridge-nf-call-ip6tables = 1 net.ipv4.ip_forward = 1 EOF
Appliquer sans reboot
sudo sysctl --system
Étape 4 : Installation de Containerd (sur tous les nodes)
Ici on utilise la méthode moderne pour gérer les clés GPG (via /etc/apt/keyrings).
1. Installer les dépendances
sudo apt-get update sudo apt-get install -y ca-certificates curl gnupg
2. Créer le dossier pour les clés
sudo install -m 0755 -d /etc/apt/keyrings
3. Télécharger la clé officielle Docker au bon format
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /etc/apt/keyrings/docker.gpg sudo chmod a+r /etc/apt/keyrings/docker.gpg
4. Ajouter le repo (support Ubuntu 24.04 Noble)
echo \ "deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.gpg] https://download.docker.com/linux/ubuntu \ $(. /etc/os-release && echo "$VERSION_CODENAME") stable" | \ sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
5. Installer containerd
sudo apt-get update sudo apt-get install -y containerd.io
6. Configurer Containerd pour utiliser Systemd Cgroup
sudo mkdir -p /etc/containerd containerd config default | sudo tee /etc/containerd/config.toml >/dev/null sudo sed -i 's/SystemdCgroup = false/SystemdCgroup = true/g' /etc/containerd/config.toml
7. Restart et activer au boot
sudo systemctl restart containerd sudo systemctl enable containerd

Je mets SystemdCgroup = true parce que Linux gère les ressources avec les cgroups. Systemd est l’init system qui a son propre cgroup manager. Si kubelet utilise cgroupfs et que le système utilise systemd, ça crée un conflit de contrôleurs, ce qui mène à de l’instabilité des nodes sous load.
Étape 5 : Installation des outils Kubernetes (sur tous les nodes)
On utilise le repo officiel K8s v1.31.
1. Télécharger la clé GPG pour K8s
curl -fsSL https://pkgs.k8s.io/core:/stable:/v1.31/deb/Release.key | sudo gpg --dearmor -o /etc/apt/keyrings/kubernetes-apt-keyring.gpg sudo chmod 644 /etc/apt/keyrings/kubernetes-apt-keyring.gpg
2. Ajouter le repo
echo 'deb [signed-by=/etc/apt/keyrings/kubernetes-apt-keyring.gpg] https://pkgs.k8s.io/core:/stable:/v1.31/deb/ /' | sudo tee /etc/apt/sources.list.d/kubernetes.list sudo chmod 644 /etc/apt/sources.list.d/kubernetes.list

3. Installer les tools et fixer les versions
sudo apt-get update sudo apt-get install -y conntrack sudo apt-get install -y kubelet kubeadm kubectl sudo apt-mark hold kubelet kubeadm kubectl
Étape 6 : Initialisation du cluster (UNIQUEMENT sur le Master node)
Exécutez la commande suivante pour initialiser le Master :
sudo kubeadm init \ --control-plane-endpoint=k8smast.lan \ --pod-network-cidr=10.244.0.0/16 \ --cri-socket unix:///var/run/containerd/containerd.sock
Pourquoi utiliser 10.244.0.0/16 et pas une autre valeur ?
C’est un détail architectural critique. Dans Kubernetes, il existe trois réseaux distincts qui ne doivent absolument jamais se chevaucher, sinon le routage (kube-proxy) sera cassé :
Le réseau physique de vos serveurs (Host Network) : C’est le réseau de votre infrastructure (généralement 192.168.x.x ou 10.10.x.x).
Le réseau des Services Kubernetes : Par défaut, kubeadm réserve automatiquement la plage 10.96.0.0/12 pour les services internes (ce qui couvre les adresses de 10.96.0.0 à 10.111.255.255).
Le réseau des Pods (défini par –pod-network-cidr) : L’utilisation de 10.244.0.0/16 est le standard de facto (parfaitement géré par Calico) car elle se place en dehors des deux réseaux précédents. Cela garantit un fonctionnement stable du cluster et évite tout conflit d’adresses IP.
(Note : Le paramètre –cri-socket garantit que kubeadm utilise bien containerd comme runtime).
ATTENTION : Il est OBLIGATOIRE de sauvegarder la commande kubeadm join affichée à la fin de l’initialisation. Elle contient le token et le hash que nous allons utiliser pour ajouter les Worker nodes au cluster.
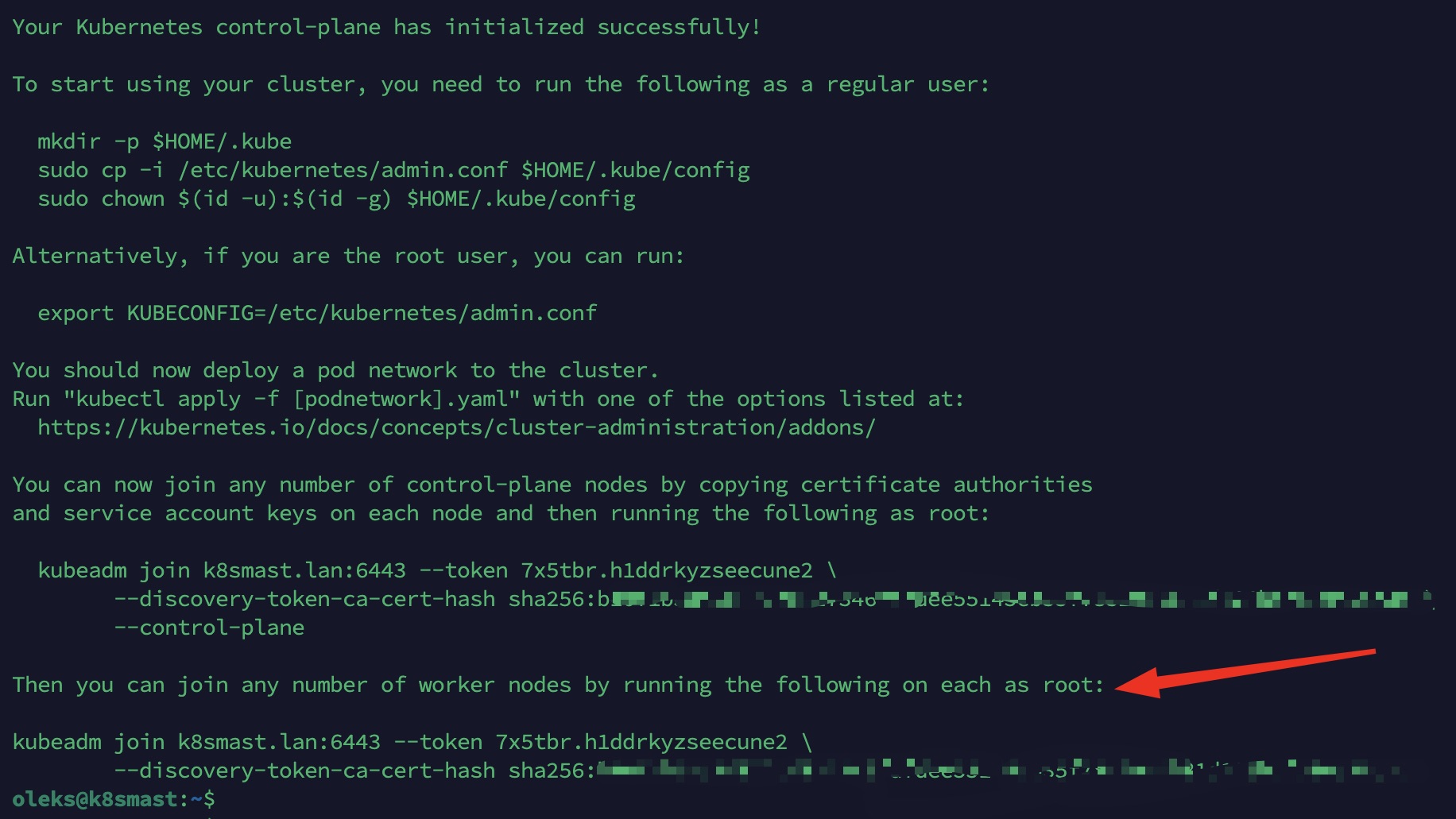
Le paramètre –cri-socket garantit que kubeadm utilise bien containerd comme runtime.
Une fois l’init terminée, configurer l’accès pour l’utilisateur :
mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config
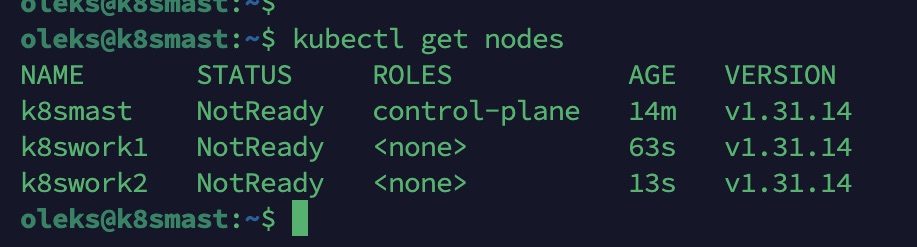
Vérifier le cluster — seul le master doit apparaître
kubectl get nodes
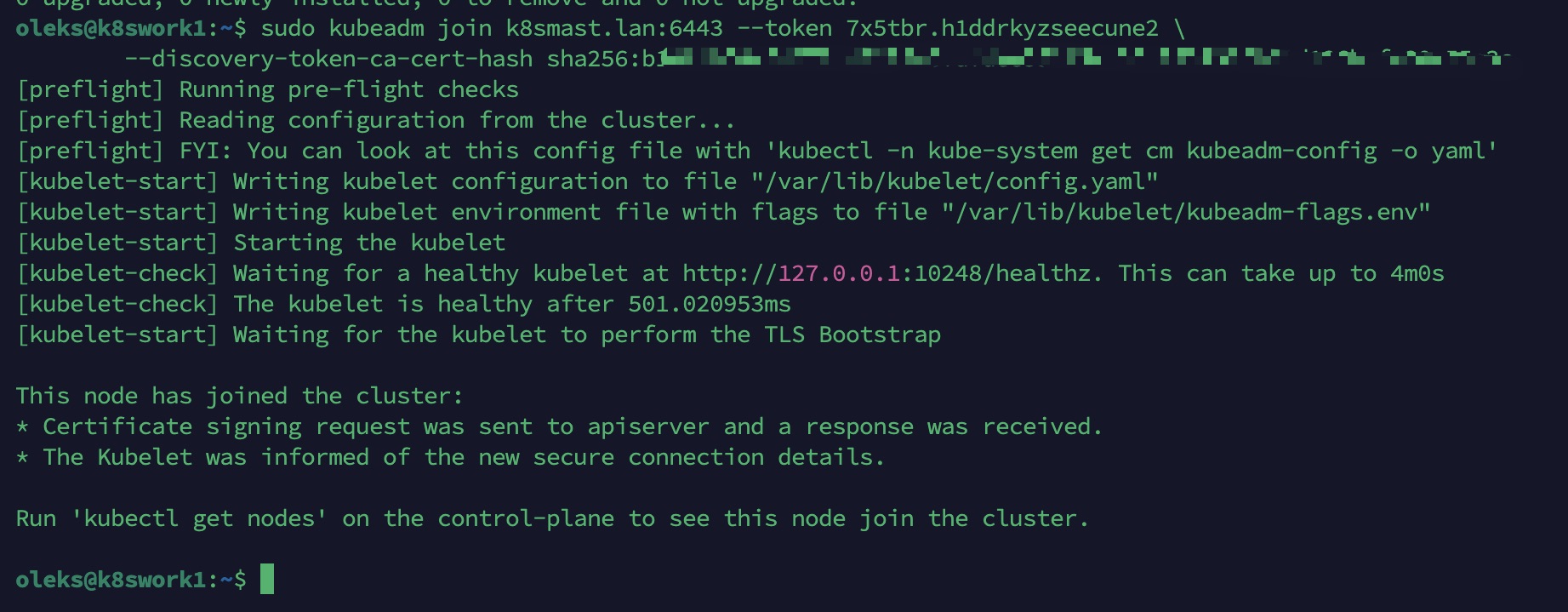
Étape 7 : Join des Worker nodes (sur Worker 1 et Worker 2)
Exécuter la commande sauvegardée à l’étape précédente (ne pas oublier sudo si nécessaire). Exemple :
sudo kubeadm join k8smast.lan:6443 --token <votre-token> \ --discovery-token-ca-cert-hash sha256:<votre-hash>
Vérifier sur le master que tout est OK
kubectl get nodes
Étape 8 : Installation du réseau CNI Calico (UNIQUEMENT sur le Master)
Dans les versions modernes de Kubernetes, le networking est beaucoup simplifié : le déploiement et la gestion du CNI passent généralement par des operators qui automatisent l’installation, les updates et le maintien des composants réseau.
Même s’il existe des alternatives (comme Cilium basé sur eBPF), dans ce tutoriel j’utilise Tigera Calico Operator parce que c’est une solution stable et éprouvée en production.
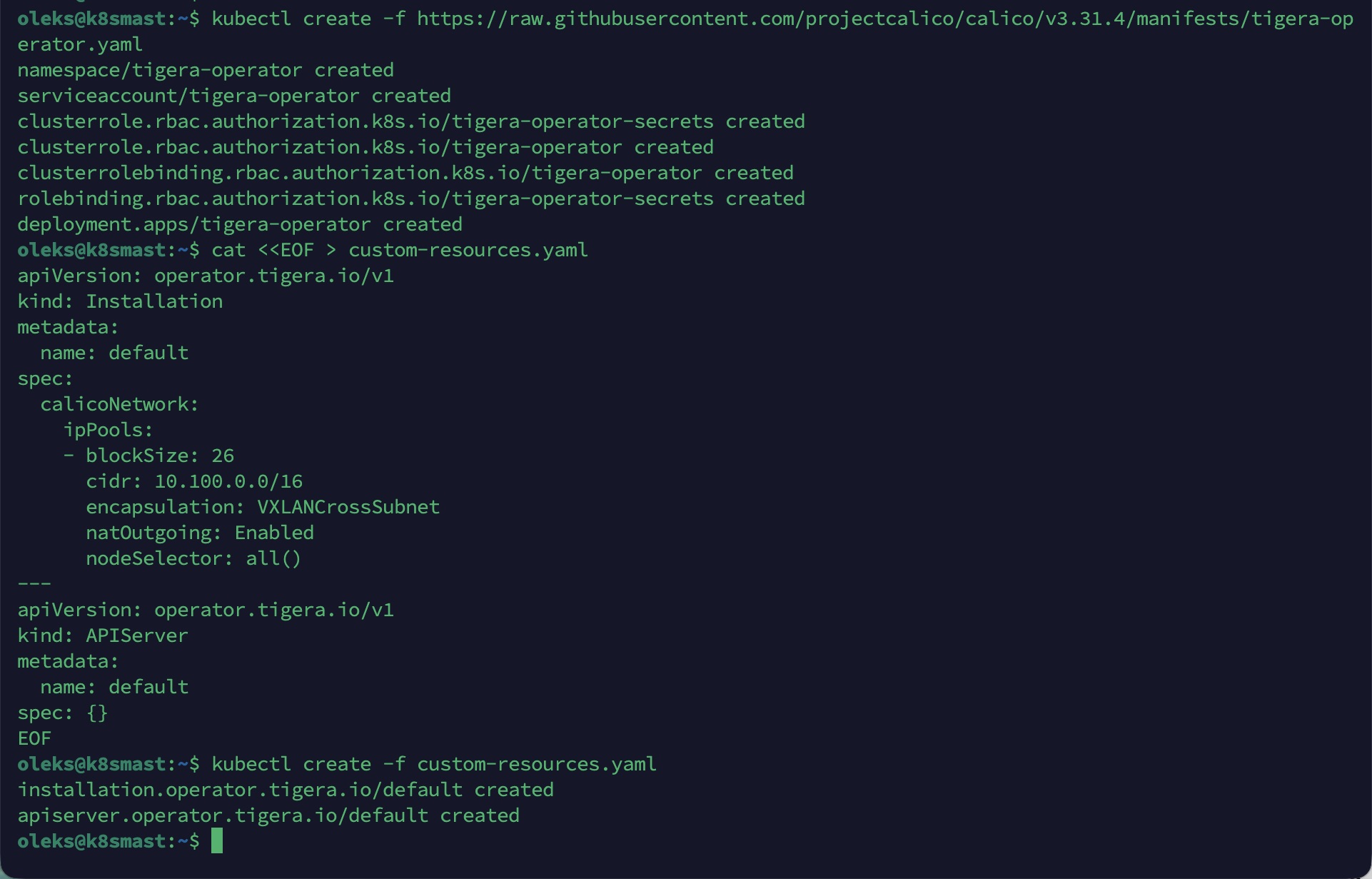
1. Installer Tigera Operator (version v3.31.4)
kubectl create -f https://raw.githubusercontent.com/projectcalico/calico/v3.31.4/manifests/tigera-operator.yaml
2. Créer les Custom Resources avec le bon CIDR (10.244.0.0/16)
cat <<EOF > custom-resources.yaml
apiVersion: operator.tigera.io/v1
kind: Installation
metadata:
name: default
spec:
calicoNetwork:
ipPools:
- blockSize: 26
cidr: 10.244.0.0/16
encapsulation: VXLANCrossSubnet
natOutgoing: Enabled
nodeSelector: all()
---
apiVersion: operator.tigera.io/v1
kind: APIServer
metadata:
name: default
spec: {}
EOF
3. Appliquer la config
kubectl create -f custom-resources.yaml
4. Vérifier le statut (attendre 2–3 minutes que tous les pods soient Running)
watch -n 2 kubectl get pods -n calico-system
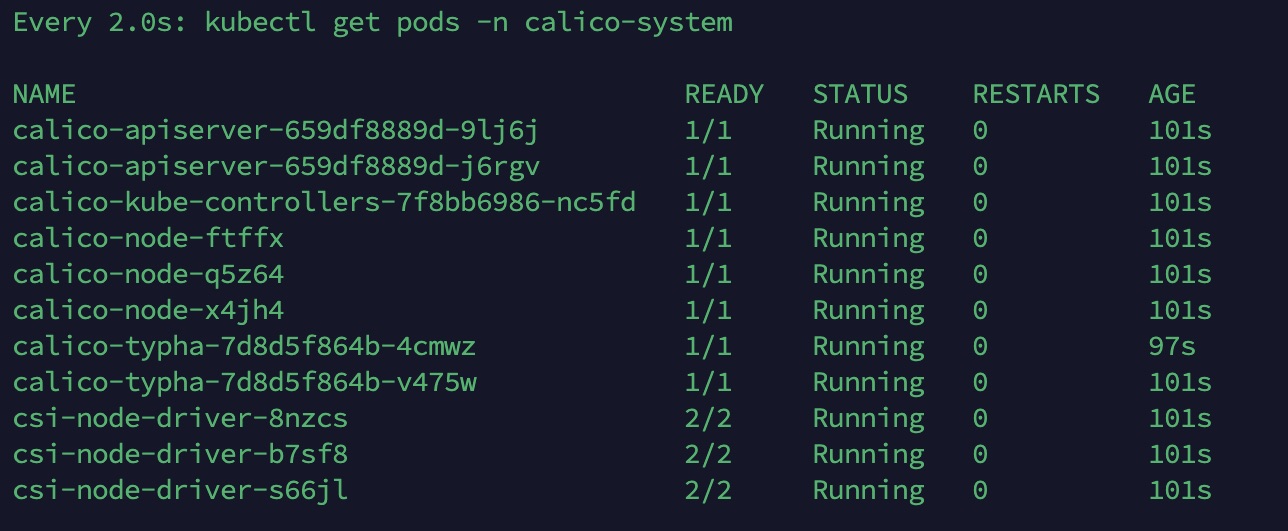
Après ça,
kubectl get nodes
doit montrer Ready pour tous les nodes.
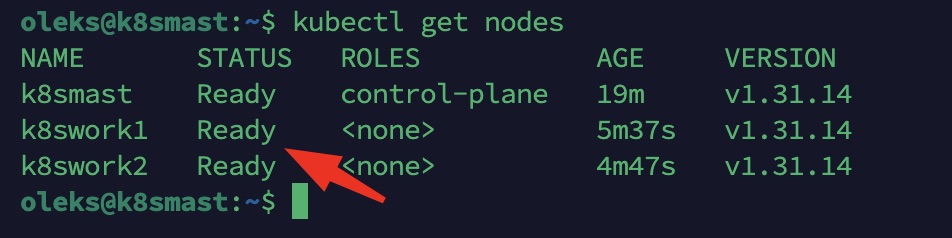
Étape 9 : Configuration correcte du firewall UFW
Configurer les nouvelles règles firewall.
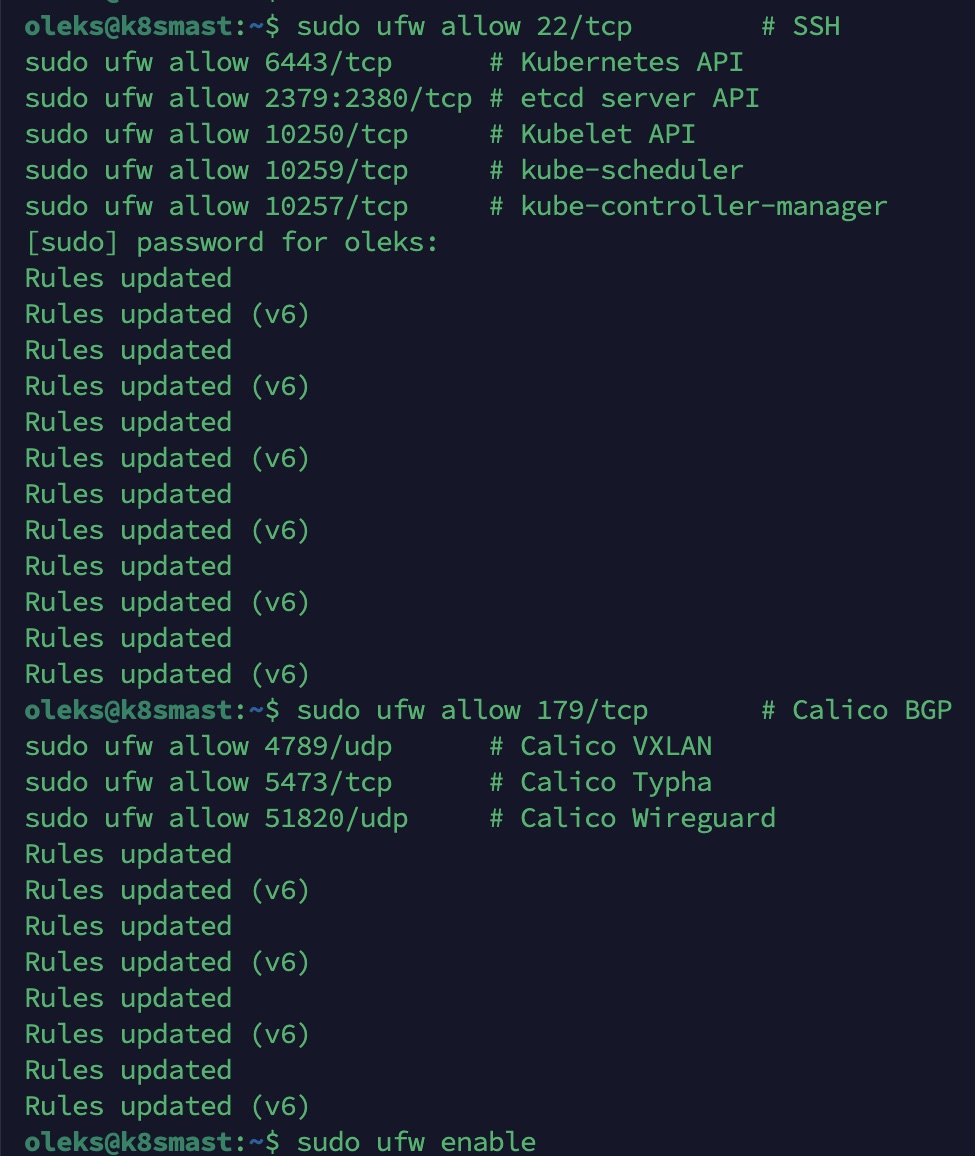
Sur le Master node (k8sm) :
sudo ufw allow 22/tcp # SSH sudo ufw allow 6443/tcp # Kubernetes API sudo ufw allow 2379:2380/tcp # etcd server API sudo ufw allow 10250/tcp # Kubelet API sudo ufw allow 10259/tcp # kube-scheduler sudo ufw allow 10257/tcp # kube-controller-manager # Calico ports sudo ufw allow 179/tcp # Calico BGP sudo ufw allow 4789/udp # Calico VXLAN sudo ufw allow 5473/tcp # Calico Typha sudo ufw allow 51820/udp # Calico Wireguard sudo ufw enable
Sur les Worker nodes (k8sw1, k8sw2) :
sudo ufw allow 22/tcp # SSH sudo ufw allow 10250/tcp # Kubelet API sudo ufw allow 30000:32767/tcp # NodePort Services # Calico ports sudo ufw allow 179/tcp sudo ufw allow 4789/udp sudo ufw allow 5473/tcp sudo ufw allow 51820/udp sudo ufw enable
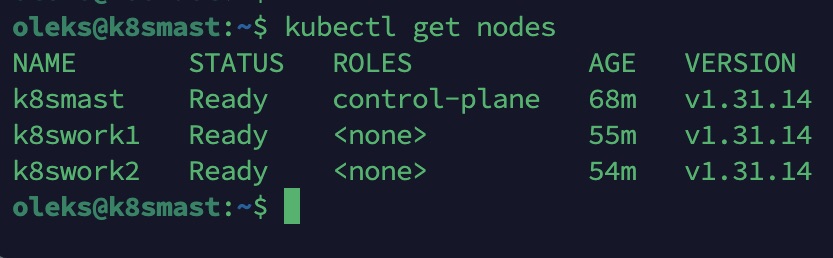
Vérifier que rien n’a cassé
kubectl get nodes
Standard d’architecture Production : Protection des nodes (Node Allocatable) et setup multi-tenant
Comme le cluster est généralement utilisé par des utilisateurs et pas juste comme un lab « démo », il faut comprendre la différence clé entre un cluster « jouet » et un environnement production.
Par défaut, Kubernetes voit 100% des ressources physiques du serveur (Capacity) et est prêt à tout donner aux containers. Si les utilisateurs lancent du code lourd avec des memory leaks, le kernel Linux active le OOM Killer (Out Of Memory) et commence à tuer des processus au hasard pour sauver le système. Ça peut inclure sshd, systemd ou même kubelet. Résultat : le node drop du cluster. Même problème avec le disque : si les pods remplissent le disk avec des logs, le serveur freeze.
Pour éviter ça, on met en place Node Allocatable et des Eviction Policies. On réserve explicitement des ressources pour l’OS et les composants système Kubernetes, en les rendant invisibles pour les pods utilisateurs, et on configure le cluster pour tuer les pods avant que ça devienne critique.
Vérifier les ressources disponibles :
kubectl describe nodes | grep -A 5 "Capacity:"
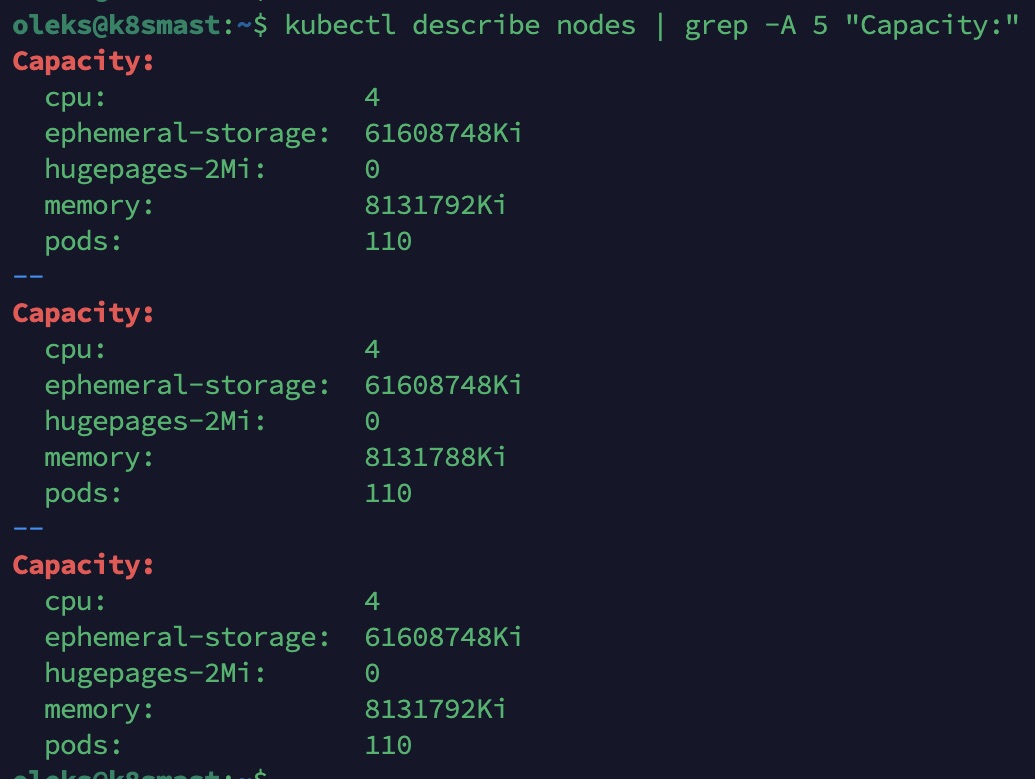
Sur chaque node, j’ai 4 CPU et 8 Go de RAM. On va sur chaque node (y compris le master) et on édite la configuration de Kubelet pour réserver 1 CPU, 1 Go de RAM et 10 Go de disque pour le système.
On ouvre le config sur chaque node :
sudo nano /var/lib/kubelet/config.yaml
On ajoute à la toute fin du fichier les lignes suivantes :
kubeReserved: cpu: "500m" memory: "512Mi" systemReserved: cpu: "500m" memory: "512Mi" ephemeral-storage: "10Gi" enforceNodeAllocatable: - pods evictionHard: memory.available: "500Mi" nodefs.available: "10%"
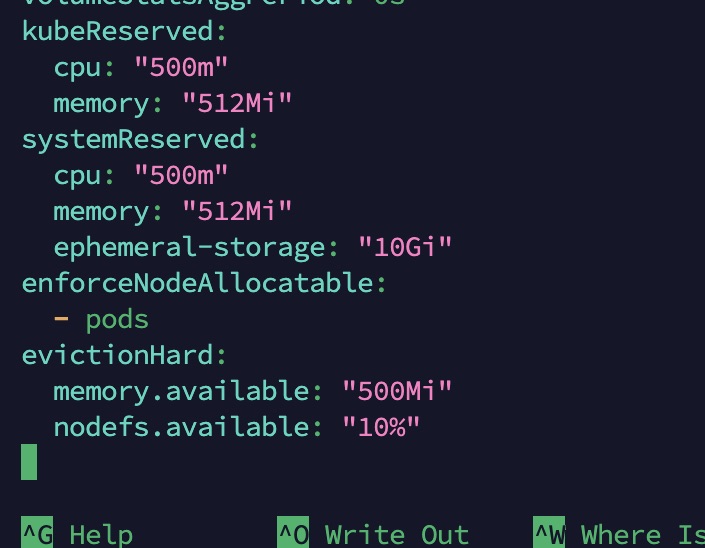
On sauvegarde le fichier et on redémarre le service :
sudo systemctl restart kubelet
Maintenant, on vérifie les configurations appliquées en exécutant la commande sur le master node pour vérifier le worker :
kubectl get nodes -o custom-columns="NODE:.metadata.name,CPU-CAP:.status.capacity.cpu,CPU-ALLOC:.status.allocatable.cpu,MEM-CAP:.status.capacity.memory,MEM-ALLOC:.status.allocatable.memory,DISK-CAP:.status.capacity.ephemeral-storage,DISK-ALLOC:.status.allocatable.ephemeral-storage"

Dans la sortie, on voit deux blocs. Dans Capacity, la capacité physique totale du serveur est affichée (dans mon cas cpu: 4 et memory: 8131792Ki). Dans Allocatable (les ressources disponibles pour lancer les pods), les valeurs doivent être exactement inférieures d’1 CPU, 1 Go de RAM et 10 Go de disque.
Grâce au paramètre evictionHard, si la mémoire libre tombe en dessous de 500 Mo ou si l’espace disque disponible descend sous 10 %, Kubelet ne va pas attendre que le système plante, mais commencera à supprimer les pods utilisateurs les plus lourds. Cela confirme que les ressources système sont correctement réservées et que les nodes sont protégés contre les crashs.
À ce stade, la préparation de l’infrastructure du cluster est terminée. L’étape suivante est la configuration de l’environnement Multi-Tenant : création de Namespaces isolés, configuration des accès (RBAC) et création d’objets ResourceQuota pour partager en toute sécurité les ressources restantes entre les utilisateurs et éviter qu’ils ne fassent planter les projets des autres. Mais c’est déjà le sujet d’un autre tutoriel.
Bonne chance!