

Si vous avez déjà ouvert Linux au moins une fois, vous avez sûrement remarqué ces dossiers un peu mystérieux comme /etc, /var, /proc, /usr, et vous vous êtes posé la question : « OK… lequel fait quoi, et qu’est-ce qui arrive si je brise quelque chose ici ? ».
Le système de fichiers Linux n’est pas un ensemble de dossiers placés au hasard, mais une hiérarchie claire et bien pensée, construite et raffinée depuis des décennies. Elle fonctionne exactement de la même façon sur un laptop à la maison, sur un serveur en datacenter, sur un VPS, dans un conteneur Docker, sur un Raspberry Pi, ou encore sur un host Proxmox ou un node Kubernetes.
Une fois que vous comprenez cette structure une seule fois, vous commencez automatiquement à comprendre n’importe quel Linux, peu importe la distribution. C’est pour ça que les sysadmins, les DevOps et les enseignants reviennent toujours sur ce sujet : c’est une base incontournable.
Dans ce guide, on va parcourir ensemble chaque répertoire, en partant de la racine /, comprendre à quoi il sert, regarder des exemples concrets tirés de la vraie vie et mentionner quelques erreurs classiques.
Alors, préparez un café ou un thé — et c’est parti ☕🐧
/
La racine (/) est le point de départ de tout le système.
Sous Linux, il n’y a pas de lettres de disque comme sous Windows, où tout commence avec le disque C:.
Sous Linux, tout fait partie d’un seul et même espace. N’importe quel disque, clé USB ou stockage réseau est « attaché » quelque part dans cette arborescence, un peu comme si on l’accrochait à une branche, grâce au mécanisme de montage (mount).
On se retrouve donc avec une vision un peu inversée de l’arbre Linux, où tout part de la racine / et se déploie ensuite en différentes branches.
/ ├── bin ├── boot ├── dev ├── etc ├── home ├── lib ├── usr ├── var └── ...

/bin
C’est une des branches de base de l’arbre Linux. Elle contient les commandes système essentielles.
Le nom bin vient de binary executables.
Ce répertoire contient un ensemble minimal de binaires nécessaires au fonctionnement du système, même en mode d’urgence. Ces commandes sont utilisées lorsque le système démarre en single-user mode, en rescue mode ou depuis un initramfs, par exemple après une corruption du système de fichiers, une mise à jour ratée ou des problèmes de montage de disques.
Dans ces situations, seules les utilitaires les plus essentielles sont disponibles : consulter des fichiers, copier des données, vérifier des disques et naviguer de façon basique dans le système. C’est exactement pour cette raison que /bin doit être accessible avant le chargement complet de /usr.
Fichiers typiques :
- ls, cp, mv, rm
- cat, echo
- bash, sh
Exemple :
/bin/ls /

Sur les systèmes modernes, /bin est souvent un lien symbolique vers /usr/bin, mais d’un point de vue logique et fonctionnel, ce répertoire reste critique pour le démarrage et le dépannage du système.
/sbin
La prochaine branche importante de l’arbre Linux est /sbin.
Le nom vient de system binary executables — ce sont des commandes système destinées à l’administration, qui agissent sur l’état global du système, et non sur un utilisateur en particulier.
On y trouve des utilitaires pour gérer le réseau, les disques et le processus de démarrage. Dans la majorité des cas, ces commandes nécessitent des droits root.
Commandes typiques dans /sbin :
- ip
- fsck
- mount
- reboot
Certaines commandes de /sbin peuvent être exécutées sans privilèges root en mode lecture seulement.
Par exemple :
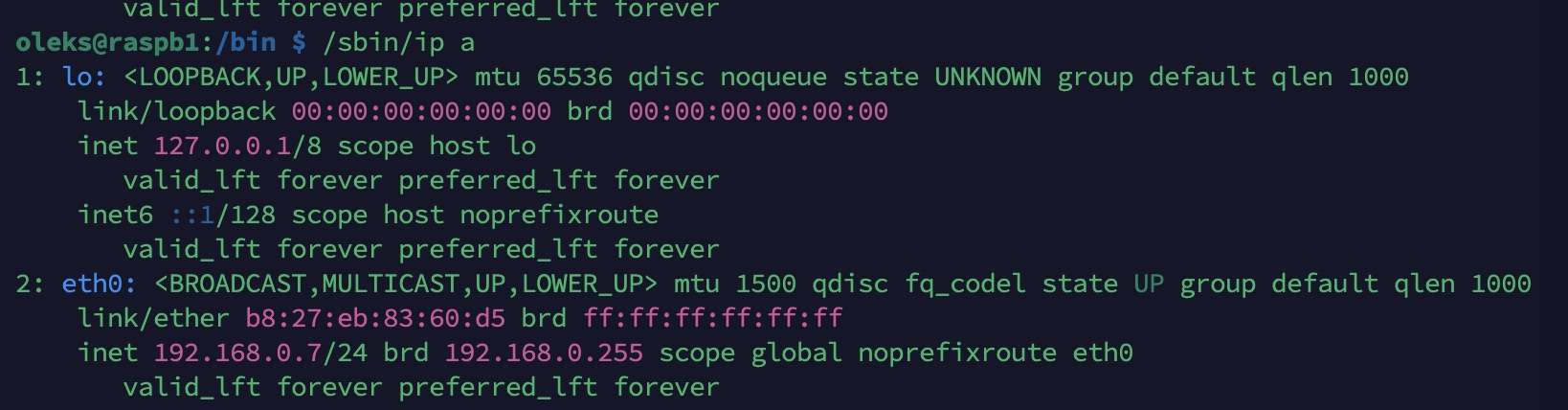
ip a
Cette commande affiche simplement l’état actuel des interfaces réseau et ne modifie rien dans la configuration du système.
Par contre, toute action qui change l’état du système nécessite des privilèges administrateur :
sudo ip link set eth0 down sudo mount /dev/sdb1 /mnt
Comparaison : ip vs /sbin/ip et fsck vs /sbin/fsck
Il n’y a aucune différence fonctionnelle entre ip et /sbin/ip (ou entre fsck et /sbin/fsck).
C’est la même commande, le même binaire.
La seule différence, c’est comment le système la trouve.
Dans un système Linux normal, les dossiers comme /bin, /usr/bin et /sbin sont déjà inclus dans la variable d’environnement PATH.
Donc quand on tape :
ip a
Par contre, dans des environnements de récupération — rescue mode, single-user mode, initramfs — le PATH est souvent très limité.
Dans ce contexte, le système ne sait pas où chercher la commande, même si elle existe.
C’est pour ça qu’on doit l’appeler avec son chemin complet :
/sbin/ip a /sbin/fsck /dev/sda1
En résumé :
- ip = version courte, utilisée quand le PATH est complet
- /sbin/ip = appel direct du binaire, utilisé quand le système est en mode minimal
- même logique pour fsck et /sbin/fsck
C’est exactement ce qu’on fait lors d’un dépannage ou d’une récupération après un problème de boot ou de disque.
/boot
La prochaine branche de notre arbre Linux est /boot — un répertoire qui contient les fichiers nécessaires au démarrage du système d’exploitation.
C’est à partir d’ici que Linux commence à démarrer, après le transfert du contrôle depuis le BIOS ou l’UEFI.
Dans /boot, on trouve généralement :
- le noyau Linux (vmlinuz-*)
- l’image du système de fichiers initial (initramfs)
- la configuration du chargeur de démarrage GRUB
On peut voir le contenu typique avec la commande :
ls /boot

Lors du démarrage du système :
- GRUB lit sa configuration depuis /boot
- il charge le noyau (vmlinuz)
- il charge ensuite l’initramfs, qui prépare le système pour accéder aux disques
- une fois cette étape terminée, le noyau passe le contrôle au système pleinement fonctionnel
C’est pour cette raison que /boot doit être accessible avant le montage du système de fichiers principal.
Il est important de se rappeler qu’après une mise à jour du noyau, de nouveaux fichiers apparaissent dans /boot.
C’est normal : Linux ne remplace pas l’ancien noyau, il ajoute le nouveau à côté.
Grâce à cela, plusieurs versions du noyau peuvent coexister, et en cas de problème, il est toujours possible de sélectionner une version précédente dans le menu GRUB.
C’est pourquoi il est recommandé de vérifier périodiquement le contenu de /boot, surtout sur des serveurs ou sur des systèmes avec une petite partition /boot dédiée. Lorsqu’elle devient pleine, on supprime généralement les anciens noyaux.
ls /boot | grep vmlinuz
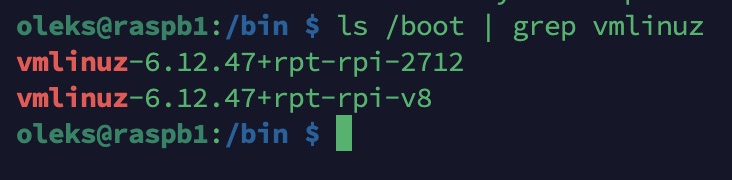
Il faut toutefois être très prudent, car les fichiers dans /boot ont un impact direct sur la capacité du système à démarrer.
La suppression ou la corruption accidentelle du noyau, de l’initramfs ou de la configuration GRUB signifie généralement que le système ne démarrera plus sans mode de récupération ou sans un live system.
En cas de problème de démarrage, il faut donc vérifier :
- qu’un noyau est bien présent dans /boot
- que la partition /boot n’est pas pleine
- que l’initramfs correspond bien au noyau installé
/dev
La prochaine branche de notre arbre est /dev.
Le nom vient de device files, c’est-à-dire les périphériques.
Sous Linux, il existe un principe fondamental : les périphériques sont des fichiers.
Disques, clés USB, terminaux, générateurs de nombres aléatoires — tout est représenté sous forme de fichiers spéciaux dans /dev.
Exemples typiques :
- /dev/sda — disque physique
- /dev/sda1 — partition sur un disque
- /dev/tty — terminal
- /dev/random — source de nombres aléatoires
- /dev/null — « trou noir » pour la sortie
Quand le système détecte un disque, il crée automatiquement un fichier correspondant dans /dev, par exemple :
/dev/sda /dev/sdb
Et pour les partitions :
/dev/sda1 /dev/sda2
Un moyen très pratique de voir ce qui est réellement connecté au système est la commande :
lsblk
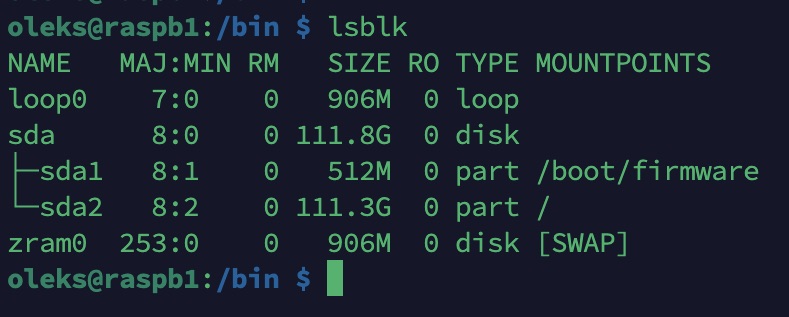
Cette commande montre quels fichiers dans /dev correspondent aux disques réels, leur taille ainsi que leurs points de montage.
Dans /dev, il n’y a pas seulement des périphériques physiques, mais aussi des pseudo-périphériques.
Par exemple :
echo "test" > /dev/null
Les données disparaissent simplement — c’est pour ça que /dev/null est souvent utilisé pour supprimer la sortie d’une commande.
Autre exemple :
cat /dev/random
Cette commande lit des octets aléatoires, utilisés entre autres pour la cryptographie.
Il est important de comprendre que le répertoire /dev n’est pas stocké sur le disque de façon classique.
Il est créé dynamiquement au démarrage du système par le mécanisme udev, en fonction des périphériques réellement présents.
C’est pour cette raison que le contenu de /dev peut changer en temps réel, lorsque du matériel est branché ou débranché.
/etc
La prochaine branche de l’arbre Linux est /etc. Elle contient les fichiers de configuration du système et des services.
Le nom vient de et cetera (« et ainsi de suite »), mais dans un Linux moderne, ce n’est plus du tout un dossier où on met « n’importe quoi » : c’est un emplacement bien défini pour la configuration.
La règle principale de /etc est simple :
on y stocke des paramètres de configuration, pas des programmes et pas des données utilisateur.
Dans la majorité des cas, ce sont des fichiers texte, lisibles et modifiables avec un éditeur.
Exemples de fichiers et de répertoires qu’on trouve souvent dans /etc :
/etc/passwd — comptes utilisateurs
/etc/shadow — hash des mots de passe (accessible seulement par root)
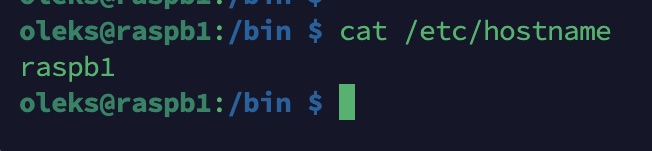
/etc/hostname — nom de la machine
/etc/hosts — correspondances DNS locales
/etc/fstab — montage automatique des disques
/etc/ssh/sshd_config — configuration du serveur SSH
/etc/network/ ou /etc/netplan/ — configuration réseau
Pour consulter un fichier, par exemple :
cat /etc/hostname
ou modifier une configuration :
nano /etc/ssh/sshd_config
On travaille avec les fichiers de /etc lorsque, par exemple, on :
- configure une adresse IP statique,
- change le port SSH,
- active ou désactive des services,
- configure un serveur web, un VPN ou un firewall.
Comme les fichiers dans /etc ne sont pas censés changer automatiquement pendant l’exécution du système, il faut généralement redémarrer le service concerné après une modification.
Par exemple, après un changement dans la configuration SSH :
sudo systemctl restart ssh
/home
Branche de l’arbre Linux où sont stockés les répertoires personnels des utilisateurs.
Chaque utilisateur possède son propre dossier :
/home/oleks /home/user01
Par exemple :
ls /home/oleks
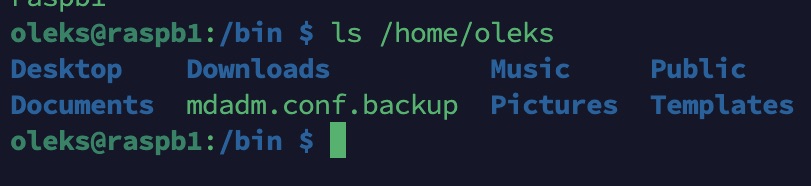
Dans le répertoire personnel, on trouve généralement :
- les fichiers et documents personnels,
- les clés SSH (~/.ssh),
- les configurations des applications (fichiers et dossiers cachés).
Ce répertoire appartient à l’utilisateur et, dans la plupart des cas, ne nécessite pas de droits root pour travailler avec ses propres fichiers.
/root
Branche de l’arbre Linux qui contient le répertoire personnel de l’utilisateur root (le superutilisateur).
Il est utilisé pour stocker les configurations, les scripts et les fichiers de l’administrateur.
À ne pas confondre avec /, qui est la racine du système de fichiers.
/lib et /lib64
Branches de l’arbre Linux où sont stockées les bibliothèques dynamiques, nécessaires au fonctionnement du noyau et des commandes système de base.
Ces bibliothèques sont utilisées par les programmes situés dans /bin et /sbin, dès les premières étapes du démarrage du système.
Exemple pour vérifier quelles bibliothèques sont utilisées par une commande :
ldd /bin/ls
Une corruption ou l’absence de fichiers dans /lib ou /lib64 peut faire en sorte que le système ne soit même plus capable d’exécuter des commandes de base.
/usr
Branche de l’arbre Linux qui contient la majorité des programmes, des bibliothèques et des ressources du système.
Le nom est historique —Unix System Resources — et n’a aucun lien avec les utilisateurs, malgré ce que le nom peut laisser croire.
Dans /usr, on retrouve l’essentiel de ce qui rend le système « complet » :
- /usr/bin — commandes utilisateur principales
- /usr/sbin — utilitaires système pour l’administration
- /usr/lib — bibliothèques utilisées par les programmes
- /usr/share — documentation, pages man, locales, icônes
Exemple :
ls /usr/bin | head
Il est important de savoir que, sur les systèmes modernes, plusieurs répertoires comme /bin, /sbin et /lib sont souvent des liens symboliques vers leurs équivalents dans /usr.
Cela signifie que /usr contient en pratique presque tout le userland du système.
Malgré cela, /usr est considéré comme statique d’un point de vue logique : on y trouve des programmes et des ressources, et non des données qui changent constamment pendant l’exécution du système.
/var
Branche de l’arbre Linux dont le nom vient de variable — données variables.
Le répertoire /var contient les fichiers qui changent constamment pendant le fonctionnement du système.
Contrairement à /usr, le contenu de /var évolue en continu et peut grossir rapidement.
On y trouve typiquement :
- les logs (/var/log)
- le cache (/var/cache)
- les données de travail des services (/var/lib)
- les files d’attente et fichiers spool (/var/spool)
Exemple pour consulter des logs en temps réel :
tail -f /var/log/syslog
Il est important de se rappeler que lorsqu’un système — surtout un serveur — manque soudainement d’espace disque, le problème se trouve très souvent dans /var, à cause des logs, du cache ou des données des services.
C’est pour cette raison que /var est fréquemment placé sur une partition séparée sur les systèmes serveur.
Dans plusieurs distributions, on peut aussi trouver le répertoire /var/www, traditionnellement utilisé pour stocker les fichiers des sites web pour Apache ou Nginx.
Le chemin réel utilisé dépend toutefois toujours de la configuration du serveur web.
/tmp
Branche de l’arbre Linux utilisée pour les fichiers temporaires.
Elle est utilisée par les programmes et les utilisateurs pour des données de courte durée.
Les fichiers dans /tmp :
- peuvent être supprimés automatiquement,
- ne doivent pas être considérés comme un espace de stockage fiable.
Très souvent, /tmp est monté en mémoire (tmpfs), ce qui signifie que son contenu est effacé au redémarrage du système.
Exemple :
touch /tmp/test.txt ls /tmp
/run
Branche de l’arbre Linux dont le nom vient de runtime — données pendant l’exécution du système.
Le répertoire /run contient des informations temporaires nécessaires au fonctionnement des services et des processus, depuis le démarrage du système jusqu’à son arrêt.
On y trouve généralement :
- des fichiers PID des services en cours d’exécution,
- des sockets pour la communication inter-processus,
- des informations sur l’état des services,
- des données runtime temporaires utilisées par systemd.
Contrairement à /tmp, /run n’est pas destiné aux utilisateurs, mais au système et aux services.
Il est créé à chaque démarrage et nettoyé automatiquement au redémarrage.
Lorsqu’un service démarre, il peut par exemple créer un fichier PID dans /run : /run/sshd.pid
Cela permet au système de savoir :
- si le service est en cours d’exécution,
- quel processus lui correspond,
- comment l’arrêter ou le redémarrer correctement.
/run est généralement monté en mémoire (tmpfs), donc :
- son contenu n’est pas écrit sur le disque,
- les fichiers dans /run ne sont pas sauvegardés,
- supprimer des fichiers manuellement peut perturber le fonctionnement des services.
/proc
Branche de l’arbre Linux dont le nom vient de process information — informations sur les processus et l’état du système.
/proc est un système de fichiers virtuel. Les fichiers qu’on y trouve ne sont pas stockés sur le disque : ils sont générés « à la volée » par le noyau pour exposer l’état interne du système.
Dans /proc, on peut trouver des informations sur :
- les processus en cours d’exécution,
- l’utilisation du CPU et de la mémoire,
- les paramètres du noyau,
- certaines informations matérielles.
Chaque processus du système possède son propre répertoire, identifié par son PID (process ID) :
/proc/1 /proc/1234
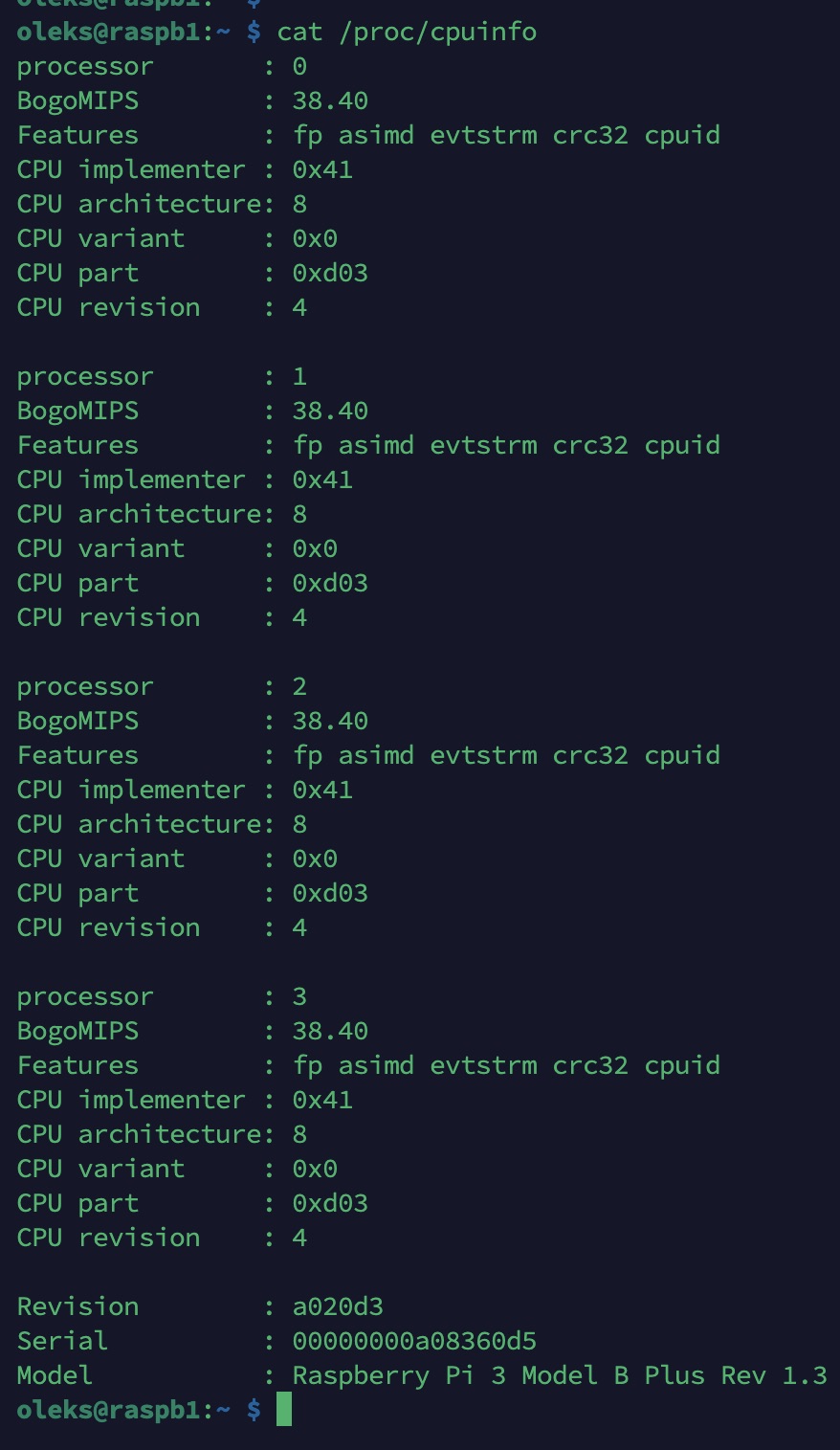
On peut par exemple y consulter des informations sur le processeur :
cat /proc/cpuinfo
L’utilisation de la mémoire :
cat /proc/meminfo
Ou encore des informations sur un processus précis :
ls /proc/1234
La majorité des fichiers dans /proc sont destinés à la lecture seulement, mais certains paramètres du noyau peuvent être modifiés en écrivant directement dans les fichiers correspondants.
Par exemple :
cat /proc/sys/net/ipv4/ip_forward
En pratique, ces changements se font généralement via sysctl, mais en arrière-plan, cela reste une interaction directe avec /proc.
Comme /proc reflète l’état vivant du système, son contenu peut changer d’une seconde à l’autre.
Les fichiers dans /proc :
- ne sont pas stockés sur le disque,
- ne sont pas sauvegardés,
- disparaissent après un redémarrage.
/sys
Branche de l’arbre Linux dont le nom vient de sysfs — system filesystem, une interface entre le noyau et le matériel.
/sys est un système de fichiers virtuel qui donne accès aux informations sur les périphériques, les drivers et certains paramètres du noyau. Comme pour /proc, les fichiers ne sont pas stockés sur le disque : ils sont créés dynamiquement par le noyau.
Dans /sys, on peut trouver :
- des informations sur le matériel,
- des paramètres liés aux drivers,
- des classes de périphériques (disques, réseau, USB),
- des réglages de gestion de l’énergie et des fréquences.
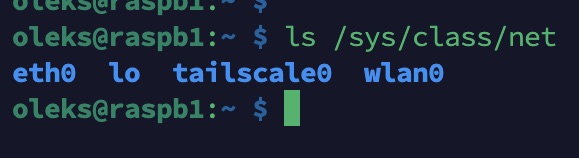
Par exemple, la liste des interfaces réseau :
ls /sys/class/net
Les informations sur les disques :
ls /sys/block

Contrairement à /proc, qui est surtout orienté vers l’état des processus et du système en général, /sys est centré sur le contrôle et la gestion du matériel.
Certains paramètres peuvent non seulement être lus, mais aussi modifiés en écrivant directement dans les fichiers correspondants (généralement avec des droits root).
Comme /sys interagit directement avec le noyau et les drivers, des changements faits sans précaution peuvent avoir un impact immédiat sur le fonctionnement du système ou des périphériques.
Les fichiers dans /sys :
- ne sont pas stockés sur le disque,
- ne sont pas sauvegardés,
- disparaissent après un redémarrage.
/mnt
Branche de l’arbre Linux dont le nom vient de mount — monter.
Le répertoire /mnt est destiné au montage manuel et temporaire de systèmes de fichiers.
Il est généralement utilisé par les administrateurs pour connecter des disques, des partitions ou des ressources réseau « pour le moment », par exemple :
sudo mount /dev/sdb1 /mnt
Traditionnellement, /mnt n’est pas utilisé automatiquement par le système et sert surtout au travail manuel et aux tests.
/media
Branche de l’arbre Linux destinée au montage automatique des supports amovibles.
C’est ici que le système monte les clés USB, les disques externes, les CD/DVD.
Exemple typique :
/media/oleks/USB_DISK
Contrairement à /mnt, le répertoire /media est activement utilisé par l’environnement graphique et par les mécanismes d’auto-montage.
/opt
Branche de l’arbre Linux dont le nom vient de optional — logiciels optionnels ou additionnels.
Le répertoire /opt est destiné à l’installation de logiciels tiers ou propriétaires qui ne font pas partie du set standard de la distribution.
En général, chaque application possède son propre sous-répertoire, par exemple :
/opt/google /opt/vmware /opt/custom_app
/srv
Branche de l’arbre Linux dont le nom vient de service — données des services.
Le répertoire /srv est destiné à stocker les données fournies par des services vers l’extérieur : sites web, données FTP, fichiers accessibles sur le réseau.
Exemples typiques :
/srv/www /srv/ftp /srv/nfs /srv/pxe
Contrairement à /var, /srv contient des données statiques de services, et non des logs ou du cache.
Dans les environnements serveur, /srv est pratique comme emplacement clairement défini pour le contenu des services.
/lost+found
Branche de l’arbre Linux utilisée par le système de fichiers (généralement ext4) pour stocker les fichiers récupérés.
Des fragments de fichiers peuvent s’y retrouver après une vérification du disque (fsck), par exemple à la suite d’un crash ou d’un arrêt incorrect du système.
Ce répertoire est créé automatiquement, il est en général vide et n’est pas destiné à une utilisation manuelle.
Voilà, nous avons fait connaissance avec le système de fichiers Linux. Derrière cette multitude de répertoires, il n’y a pas de magie, mais une logique affinée au fil des années. Une fois comprise, elle permet d’administrer le système avec confiance, de trouver rapidement les problèmes et de se sentir à l’aise sous Linux, comme chez soi.
Bonne chance !